最近因为在折腾了一下比特币的钱包功能相关开发工作,搭建环境的时候遇到了一些坑,因此记录下来,以备不时之需。
在比特币的大系统里存在三个独立的网络链系统:比特币主链系统、测试链系统、回归测试链系统。
主链系统就是生产环境正在跑的网络,也是矿工工作的网络。测试链系统也是在公共网络跑的节点,只不过节点比较少,仅仅用来线上测试。
回归测试链系统常用来做开发调试使用,也就是这儿所说的“私链”,在这里你所有的操作都只能在本地生效,不会影响线上。
一个正在觉醒的无名氏修行者,略懂编程,略懂音乐。
最近因为在折腾了一下比特币的钱包功能相关开发工作,搭建环境的时候遇到了一些坑,因此记录下来,以备不时之需。
在比特币的大系统里存在三个独立的网络链系统:比特币主链系统、测试链系统、回归测试链系统。
主链系统就是生产环境正在跑的网络,也是矿工工作的网络。测试链系统也是在公共网络跑的节点,只不过节点比较少,仅仅用来线上测试。
回归测试链系统常用来做开发调试使用,也就是这儿所说的“私链”,在这里你所有的操作都只能在本地生效,不会影响线上。
Jenkins是基于Java开发的一种持续集成工具,功能非常强大,可以让程序员从繁杂的项目部署的工作中抽离出来。
首先去官网下载安装安装包,下载地址:https://jenkins.io/download/

你会发现,Jenkins 提供了两种不同的版本供你下载,一种是 Long-term Support(长期支持版本),也就是我们常说的 LTS 版本,推荐安装这种,
另一种是周期性更新的版本,Weekly, 这中发行版迭代周期会快一些,但是通常不会很稳定.
Jenkins 针对不同的系统提供了不同的便捷安装方式,比如如果你是 Ubuntu 系统的话,就可以采用如下方式安装:
1 | wget -q -O - https://pkg.jenkins.io/debian-stable/jenkins.io.key | sudo apt-key add - |
不过我通常喜欢直接用最简单的方式,直接下载 Generic Java package (.war) 来安装。下载完成之后,直接运行:
1 | nohup java -jar jenkins.war > output.log & |
这样就启动了。在浏览器地址栏输入 http://localhost:8080 就可以开始初始化安装。
当然,既然是 war 文件,你也可以直接把它丢到 tomcat 的 webapps 文件下运行。但是那样一则麻烦,二则你访问的地址就要变成
http://localhost:8080/jenkins 了。
首先输入初始密码,页面有提示你初始密码的保存位置,打开密码文件,复制粘贴进来就好了。

输入密码成功之后,会让你选择安装插件,新手就选择左面那个安装推荐的插件就OK了

装完插件之后,会让你选择创建账号,你也可以先用admin,以后需要再创建新账号。
在进行项目部署之前,我们需要确保已经安装了 Git plugin 和 Publish Over SSH 这两个插件,如果没有安装的话,通过菜单 系统管理 -> 插件管理 安装。

在插件管理页面通过搜索关键字,找到索要安装的插件,选中安装就可以了

由于我们的项目需要通过 publish Over SSH 连接服务器发布,所以我们先要配置 Publish Over SSH, 进入菜单 系统管理 -> 系统设置, 找到Publish Over SSH 添加你需要发布到的服务器的连接信息。

做完这些之后,记得把部署 jenkins 所在的服务器的公钥放在要部署的目标服务器的 ~/.ssh/authorized_keys 文件中.
点击新建任务, 输入项目名称,选择 构建自由风格的软件项目,按照下图配置:

配置好之后,在目标服务器的 Jenkins-in 目录下新建一个 xxxx-deloy.sh 也就是上图中最后一栏中填写的的项目部署脚本,这个脚本里你可以编写
任意的 shell 脚本帮你完成项目的部署,非常方便。下面贴出我的一个测试项目的部署脚本,仅供参考:
1 |
|
接下来就可以执行构建了。
岁月如梭,时节如流,2018年已经进入尾声了,2019已经来临,作为一个有追求的自由人,是该做年终总结的时候了。
为什么我们要写总结呢?
一个简单的回答是:你需要对自己过去的一年有个交待。
一个装逼的回答是:未经审视的人生不值得度过。我们需要通过年终总结来自我反省,自我更新迭代,成为更好的自己。
最近在折腾 Go 语言的时候,经常需要使用 go get 来下载和安装第三方库或软件。
经常会碰到 go get 无法访问,之前在编译 Filecoin 和 EOS 项目的时候也常常因为无法 clone Github 上的一些开源项目(如 MongoDB) 而导致编译失败,
因为这些第三方库或软件或项目对应的网站在国内无法访问,或者访问速度比较慢。所以设置一个终端代理就变得非常有必要了。
原理:很多人都代理软件是基于 socks5 协议的。而
go get和git clone都是使用 http 协议。所以我们需要一个中间代理,把 socks5 协议转为 http 协议。
在 Github 上找到一个牛人开发的项目 cow, 安装之后简单配置就可以使用了。
COW 的设计目标是自动化,理想情况下用户无需关心哪些网站无法访问,可直连网站也不会因为使用二级代理而降低访问速度。
安装方式非常简单, Linux 和 OSX 系统直接执行下面的命令:
1 | curl -L git.io/cow | bash |
修改配置文档 vim ~/.cow/rc
1 | #开头的行是注释,会被忽略 |
修改 vim ~/.bashrc,在文件末尾加上下面代码,导出环境变量
1 | export http_proxy=http://127.0.0.1:7777 |
然后启动你本机的代理软件。
至此,恭喜你,你的终端可以很流畅的访问 Github 了。
本文简单介绍一下 Filecoin 的工作原理以及工作流程,让读者可以对整个 Filecoin 去中心化存储解决方案有个大概的认知。如果想要详细深入了解细节的,
请阅读 Filecoin 和 IPFS 白皮书(在文末参考文献中有链接)。另外,本文为作者完全原创,转载请注明来源,谢谢。
 {:style=’height:40px;display:inline !important;’}
{:style=’height:40px;display:inline !important;’}
Filecoin 是一个去中心化的存储网络,简称 DSN(下面我们称之为 Filecoin 网络), 她将全球的闲置的存储资源转变为一个存储算法市场,
其最终目标是创建一个永久的,安全的,不受监管的新一代存储网络。
在 Filecoin 的网络里,矿工通过提供存储或者检索资源来赚钱 Token(FIL), 客户付钱给矿工存储或检索数据。
Filecoin 和 IPFS 都是 IPFS 协议实验室提出的,他们属于同门师兄弟,Filecoin 是 IPFS 的补充协议。IPFS 作为一个开源项目已经被很多系统在使用,
它允许节点之间相互请求,传输,和存储可验证的数据,但是节点之间并没有形成一个统一的网络,各个节点都是各自存储自己认为重要的数据,
没有简单的方法可以激励他人加入网络或存储特定数据。
Filecoin 的出现就是为了解决这一关键问题,它旨在提供一个可以用来持久存储的系统,作为 IPFS 的激励层。
至于 Filecoin 是如何解决这个问题的,我们会在后面详细讲解。
Filecoin 的架构可以简单拆分成两个模块,一个去中心化存储市场,一个是区块链
Filecoin 的 DSN 主要包含 4 个角色:
任何节点都可以同时扮演这四个角色,但也可以选择仅扮演其中某一个或者几个角色。
区块链是一个公开的分布式账本,不依赖中央权威机构,而是由成千上万个自由节点组成的网络,每个节点都参与网络并通过特定的共识协议来达成决策。
Filecoin 作为一条公链,它记录整个 DSN 网络中所有的交易订单,复制证明,时空证明等重要的交易凭证,所有这些数据不可篡改,作为用户和矿工维权的证明。
在共识协议上 Filecoin 采用的是 POS(Proof-of-Storage) 共识算法,注意这个并不是以太坊的 POS(Proof of Stake),前者是基于存储证明,后者是基于权益证明。
这也说明作为 Filecoin 矿工,如果你的存储能力越强,你挖到区块的概率就会越高。
值得一提的是,Filecoin 主链的架构跟以太坊设计的很相似,Filecoin 中的 message 大致相当于以太坊交易,而 Filecoin actor 与以太坊智能合约类似。
甚至还引入了以太坊中 Gas 这个概念。
这里可能有同学对 Filecoin 中的 message 和 actor 有点懵逼,这里简单解释一下,其实 message 你可以把它理解成一条信息,比如 A 向 B 转一笔账,
然后 Filecoin 就往区块链上记录一条 message, 就像以太坊上发送一笔交易(send a transaction) 一样。
Actor 比较难解释,我们先看 Filecoin 项目中源码是怎么定义 actor 的:
1 | // Actor is the central abstraction of entities in the system. |
代码注释写的很清楚,它其实就是整个区块链系统中涉及到的实体的一个抽象,学过面向对象编程的同学可以把它理解成一个基类,就像 Java 中的 Object,
它是所有其他实体的父类。这些实体包括 Accounts(账户), Contracts(智能合约)等。
Actor 定义一些基础字段:
从
Actor的数据结构我们可以看出,合约账户也是有余额的,也就是说我们也可以往合约中转入 FIL 代币,
这个跟以太坊是一模一样,所以预测 Filecoin 的智能
合约功能应该也是比较强大的,开发者可以基于它开发强大的第三方去中心化存储的 DAPP。
接下来讲(敲)重(黑)点(板)了,不了解 Filecoin 存储流程的矿工不是好的程序员。毕竟假如 Filecoin 这个 DSN 网络真能稳定跑起来,
那么理论上是人人都可以是矿工的。
在讲工作流程之前我们简单介绍一下 Filecoin 中几个基本的数据结构,这对我们理解下面的存储流程很有帮助。
Pieces: 数据单元,是 Filecoin 网络中最小存储单位,每个 Pieces 大小为 512KB, Filecoin 会把大文件拆分成很多个 Pieces,Sectors: 扇区,矿工提供存储空间的最小单元,也就是说在我们创建矿工的时候抵押存储空间大小必须是 SectorAllocationTable: 数据分配追踪表,它记录了每个 Pieces 和 Sector 的对应关系,如某个 Pieces 存储在了哪个 Sector.Orders: 订单,系统中有两种订单,一种是竞价订单(bid order), 由客户发起,另一种是要价订单(ask order), 由矿工发起。Orderbook: 订单簿,也就是订单列表,包括 bid order 和 ask order,系统根据订单列表进行自动撮合匹配交易。Pledge: 抵押,矿工必须需要向 Filecoin 网络抵押 FIL 代币才能才能开始接受存储市场的订单。理解一个复杂的概念最好的办法就是把它拆解成多个简单易懂的简单概念。首先我们看下 Filecoin 白皮书上提供的一张关于 DSN 网络工作流程的图片。
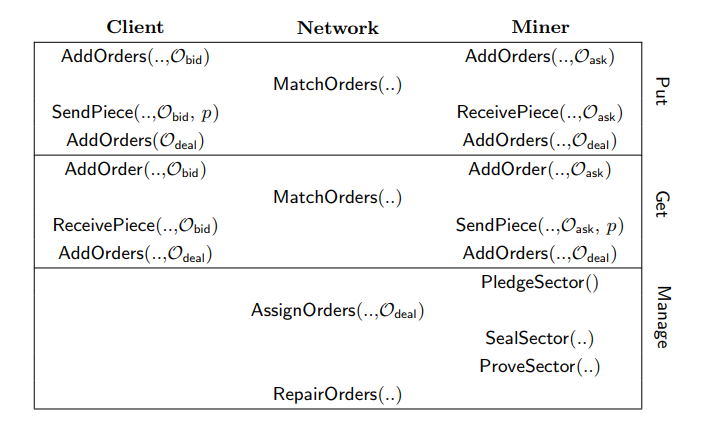
通过这张图我们可以从横向(操作)和纵向(角色)来了解整个流程。我们对文件的操作无非就两种,存(Put)和取(Get), 而这两种操作分别对应两种角色,客户和矿工。
外加一个区块链网络和市场管理者(Manage), 这就构成了整个 Filecoin 的 DSN 网络,具体交易流程如下。
(1)客户和矿工分别发送一个竞价订单和出价订单到交易市场(Market),这里需要注意的是,如果是 bid order,
需要注明你这个文件的存储时间(比如三个月), 以及需要备份的数量(比如 3 份),备份数量越多,文件丢失的概率就越低,当然价格也就更高一些。
(2)交易网络管理中心(Manage)分别验证订单是否合法,如果是竞价订单,系统会锁定客户资金,如果是出价订单,系统会锁定矿工的存储空间。
(3)分别执行 Put.MatchOrders 和 Get.MatchOrders 进行订单撮合,成功之后会运行 Manage.AssignOrders 来标记该订单为
Deal Orders(成交订单),
并在 AllocationTable 中记订单的 Pieces 和 Sector 信息。
(4)执行文件的 Put 操作,即把文件存储到矿工的硬盘,并生成 PoRep(复制证明)发送给交易网络存储到区块链。
(5)矿工需要定期(every epoch)需要向交易网络发送PoSt(时空证明)来证明你这段时间确实存储了指定的文件,交易网络在验证之后,支付你相应费用(FIL).
至此,整个存储交易流程就完成了,矿工需要注意的并不是你存储了数据,交易就会把币打给你,而是通过小额支付(Micro pay)的方式分次支付给你。
1 | 比如 Rock 需要把他的照片一共10GB存储一年,出价 12 个 FIL 代币,然后你接了这笔订单,交易网络的 epoch 设置是一个月,那么你每个月都要向交易网络提供 |
不过检索矿工是服务一次之后就可以收到订单的所有费用,因为一次检索服务执行完之后,整个交易就完成了。
整个 Filecoin 最核心的概念某过于复制证明和时空证明了,事实证明,这也是这个系统难点所在,根据 Filecoin 测试网络的测试结果来看,如何快速生成
有效的复制证明和时空证明,将是整个项目最大的挑战。本文只是对这两个概念的定义做下简单说明,如果想要研究其核心算法,请阅读下面的参考文献。
复制证明(PoRep)是一种新颖的存储证明,它允许服务器(即证明者P)说服用户(即验证者V)某些数据D已被复制到其自己的唯一专用物理存储设备上了。
Filecoin 是通过一个交互协议完成:
复制证明只能证明你当时接单的时候确实存储的用户的文件,但是矿工可能一转身就把数据转移到其他地方去了,这就是 Filecoin 中所说的外包攻击,即你自己并没有
存储客户的数据。那么如何证明你确实在这段时间内实实在在存储了指定的数据呢? 时空证明(PoSt)就是为了解决这个问题。
简单来说就是要求存储矿工每隔一段时间(例如5分钟)来发送一次存储证明到区块链网络, 但是 Filecoin 每次交互的通信都比较复杂,有各种加密签名,如此频繁的
网络通信将会成为整个系统的瓶颈,所以需要调整 epoch(时间间隔) 的值,使系统达到一个平衡点,或者使用其他的更优的解决方案。
不得不说,Filecoin 确实是一个伟大的构想,如果落地了将会是一个很好的去中心化存储网络的解决方案,能降低存储成本和带宽成本,
提升了资源的使用效率。但是它的整个工作流程(相对于传统的中心化存储)有点复杂了一些,还就是从技术的层面,它还有一些问题,
比如 nat 穿透问题(这是 IPFS 的问题),PoSt 的算法也需要进一步优化才能应用到工程层面。
Filecoin 社区发展还比较快,开发者也比较活跃,说明业界对它的关注度还是
比较高的。目前开发者都在积极的帮助测试和优化项目,据说新的复制证明的生成算法已经将效率提高了接近一倍。
所以个人觉得整个项目的前途是光明的,只是通往光明的道路从来都是曲折的。
Genymotion 一款优秀的 Android模拟器 工具,它体积小,启动快,配置简单,功能强大,能快速构建出各种 Android 版本的模拟器。
本文讲述如何构建 Filecoin 网络统计项目(filecoin-network-stats)
filecoin-network-stats 是一个用于跟踪 Filecoin 网络状态的可视界面。它包含两个项目,前端仪表盘 和 后端信息统计收集服务 。
前端的部署特别简单,首先切换到 front 目录,然后执行构建就好了。
1 | cd front |
前端项目启动后默认会将 http://127.0.0.1:8081 作为后端服务 API 的请求地址,由于我们目前还没有部署后端,所以前端页面暂时无法访问。
如果你想更改后端 API 的 url 可以通过下面的命令来实现:
1 | BACKEND_URL=<your-backend-url> webpack-dev-server --hot |
前端仪表盘每隔 5 秒钟向后端发送 http 请求更新一次数据。
先切换到后端目录 backend
然后安装依赖模块
1 | npm install |
构建项目
1 | npm run build |
如果你计算机上没有安装 PostgreSQL 请先安装:
1 | sudo apt-get install postgresql # 安装服务端 |
然后创建用户和数据库
1 | sudo su - postgres |
PostgreSQL 的入门教程请点击 这里{:target=”_blank”}
然后,创建 peerId.json 文件,在 backend 目录下运行以下命令:
1 | node -e "require('peer-id').create({ bits: 1024 }, (err, id) => { if (err) { throw err; } console.log(JSON.stringify(id.toJSON(), null, 2))})" > peerId.json |
在启动之前,你首先需要在 backend 目录下创建一个环境变量文件 .env:
1 | export DB_URL=<your-postgres-url> |
关键变量解释:
| 变量名称 | 变量说明 |
|---|---|
| DB_URL | PostgreSQL 数据库连接地址,一般格式为 postgresql://{user}:{pass}@{host}:{port}, 跟 MySQL 的有点像 |
| FULL_NODE_URL | 全节点的 API 地址,一般为 http://{host}:3453, {host} 为你的全节点服务器的 IP 地址 |
| PEER_INFO_FILE | 节点信息文件,就是前面我们创建的 peerId.json 文件,不用修改 |
| HEARTBEAT_PORT | 接收节点心跳的端口,所有节点都需要通过这个端口推送改节点的相关信息 |
| API_PORT | API 端口,这个是只给前端项目 (front) 提供服务的 API 服务的端口 |
| LOG_LEVEL | 日志等级,默认是 info,只打印重要信息,更改为 silly 可以打印更详细的信息 |
下面贴上我的完整配置:
1 | export DB_URL=postgresql://filecoin:123456@localhost:5432 |
接下来你需要迁移数据库:
1 | DATABASE_URL=<your database url> db-migrate up |
这里的 DATABASE_URL 跟上面一样
@Note: 如果这里你碰到权限错误的话,建议先迁移到超级用户 postgres,然后再通过导出,导入命令实现。
1 | pg_dump --host 127.0.0.1 --port 5432 --username postgres > db.sql postgres # 导出 |
Note: 如果你的全节点是私有链的话,建议先把除
ip_to_locations之外的所有数据表的数据都清空,否则会有些报找不到区块的异常,因为你测试数据上已经有
10000 多个区块了。
现在万事俱备,可以启动后端节点了:
1 | source ./.env && node ./dist/src/main.js |
启动成功之后,你就可以开始收集矿工信息了,要收集有关节点数量和位置的统计信息,请让矿工设置其节点的 heartbeatUrl 和昵称,如下所示:
1 | go-filecoin config heartbeat.nickname '"Pizzanode"' |
<your-backend-domain-name> 可以使用域名也可以使用 IP 地址,如果你使用的是 IP 地址,请把前面的 dns4 协议改成 ip4<your-peer-id> 指的是 peerId.json 文件中的 ID 字段,而不是全节点的节点 ID比如我的 peerId.json 文件中的 ID 为 QmbUAMCS9bknw5tG4BTpDRsGxFSnvbCqgA6uo8Hvx1wcHc,然后我的几个节点和 filecoin-network-stats 后端服务都是
部署在同一台服务器,所以我设置的 heartbeatUrl 为:
/ip4/127.0.0.1/tcp/8080/ipfs/QmbUAMCS9bknw5tG4BTpDRsGxFSnvbCqgA6uo8Hvx1wcHc
现在你访问前端仪表盘页面: http://localhost:8082 就可以看到统计数据了,下面贴上我的部署成功之后的最终效果图:
矿工统计页面:
::: motto
IPFS 将对互联网协议进行一次重塑,互联网将进入 web3.0 时代。
:::
本文我们聊一聊 ipfs 如何能助力让互联网进入 web3.0 时代。
容器(docker)是一个伟大的创新,它将我们带入了云原生的时代。使得环境搭建,应用的部署变得异常简单,方便。使用容器我们可以很轻松的搭建
我们的集群应用和微服务。
本文主要讲述如何在容器中运行 ipfs 节点。
本文讲述如何使用 IPFS 搭建自己的私有存储网络,如果你对 IPFS 还了解的话,建议你先看看下面两篇文章