本文介绍如何搭建 Ceph 的文件系以及 CephFS 的相关操作。
CephFS 简介
CephFS 简称 Ceph 集群文件系统。在介绍 Ceph 文件系统之前,首先我们了解一下什么是计算机的文件系统。
计算机的文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易,文件系统使用文件和树形目录的抽象逻辑概念代替了
硬盘和光盘等物理设备使用数据块的概念,用户使用文件系统来保存数据不必关心数据实际保存在硬盘(或者光盘)的地址为多少的数据块上,
只需要记住这个文件的所属目录和文件名。
简单的说,文件系统是一套实现了数据的存储、分级组织、访问和获取等操作的抽象数据类型。
Linux 系统下的 ext3,ext4,xfs ,以及 windows 下的 ntfs,U 盘的 fat32 都是我们常见的文件系统。
通常我们在我们要使用硬盘/U盘存储数据之前要先格式化,其实就是在磁盘上初始化一个文件系统。
所以我们通常也把 ext4, ntfs 这些叫做磁盘做磁盘的格式。
理解了文件系统的概念之后我们就可以解释什么是 CephFS 了。所谓 CephFS 就是 Ceph 集群自己实现的文件系统,
用来组织和管理集群的存储空间。是个 POSIX 兼容的文件系统,它使用 Ceph 存储集群来存储数据,本质上跟上面的 ext4, ntfs 没什么两样。
只不过这个文件系统能够依托 Ceph 集群的优势,方便扩展,并且能够提供优异的读写性能。
使用起来也非常方便,用户可以直接将Ceph集群的文件系统挂载到用户机上使用。
启用 CephFS
Ceph 文件系统至少需要两个 RADOS 池,一个用于数据,一个用于元数据。
启用 MDS 服务,这里我们是用 ceph1 节点运行 MDS 服务:
1 | ceph-deploy mds create ceph1 |
Note: Ceph 集群允许创建多个
MDS服务,但是默认只允许启动一个MDS,其他都都作为热备状态。
1 | root@client:~# ceph -s |
standby 状态的 MDS 节点都是座位热备服务。
创建数据 Pool:
1 | ceph osd pool create cephfs_data 128 |
创建元数据池:
1 | ceph osd pool create cephfs_metadata 128 |
启用 cephfs:
1 | ceph fs new cephfs cephfs_metadata cephfs_data |
查看 cephfs:
1 | root@client:~# ceph fs ls |
最稳定的配置
为了营造一个 “健康快乐” 的文件系统,要使用单个活跃 MDS 并且不要用快照功能,这两条都是默认的:
- 快照默认是禁用的,除非管理员通过
allow_new_snaps选项明确打开了。 - Ceph 默认会使用单个活跃 MDS ,除非管理员明确设置了大于 1 的
max_mds值。需要注意的是,
创建额外的 MDS 守护进程(比如用ceph-deploy mds create命令)完全没问题,因为它们默认处于热备状态。
启用standby-replay模式也是很安全的。
CephFS 挂载
客户端挂载 cephfs 有两种方式,kernel driver 和 fuse
- fuse 客户端最容易与服务器做到代码级的同步,但是内核客户端的性能通常更好。
- 这两种客户端不一定会提供一样的功能,如 fuse 客户端可支持客户端强制配额,但内核客户端却不支持。
- 遇到缺陷或性能问题时,最好试试另一个客户端,以甄别此缺陷是否特定于客户端
1. 内核挂载
默认 Ceph 是启用 cephx 认证功能的。所以我们需要先导出认证的 keyring:
1 | root@client:~# ceph auth export client.admin |
拿到 keyring 之后就可以直接挂载了:
1 | root@client:~# mount -t ceph 192.168.2.201:6789:/ /mnt/cephfs -o name=admin,secret=AQBMiTle2FjIFBAA3dQ7SssZS9Ged+o8yu2HgA== |
当然你也可以关闭认证,直接修改 /etc/ceph/ceph.conf 文件,将 cephx 改成 none:
1 | auth_cluster_required = none |
这时候就可以直接挂载了:
1 | mount -t ceph 192.168.2.201:6789:/ /mnt/cephfs |
这里的 192.168.2.201 是 MDS 服务运行的节点 IP,这里也可以直接换成 ceph1
设置开机自动挂载
先保存 keyring 到文件:
1 | echo AQBMiTle2FjIFBAA3dQ7SssZS9Ged+o8yu2HgA== > /etc/ceph/admin.key |
修改 /etc/fstab,追加:
1 | 192.168.2.201:6789:/ /mnt/cephfs ceph name=admin,secretfile=/etc/ceph/admin.key,noatime,_netdev 0 0 |
2. fuse 挂载
先安装挂载工具:
1 | apt-get install ceph-fuse |
执行挂载:
1 | root@client:~# ceph-fuse -m ceph1:6789 /mnt/cephfs |
设置开机自动挂载
同样需要将存储节点的 admin 秘钥拷贝到本地,参考上文。
然后修改 /etc/fstab 文件,加入:
1 | id=admin /mnt/cephfs fuse.ceph defaults 0 0 |
例如:
1 | id=admin /mnt/cephfs fuse.ceph defaults,_netdev 0 0 |
RBD VS CephFS
你可能发现了,CephFS 是个 POSIX 兼容的文件系统,它在挂载后跟块设备(RBD) 的使用方式没有什么区别。
而且 RBD 的空间容量也是可大小,调整起来非常方便,同时也具有优秀的读写性能。
咋一看他们用起来差不多,貌似如果已经有了 RBD,Ceph 文件系统看起来没有什么必要了,有点多余。
主要是因为应用场景的不同,Ceph的块设备具有优异的读写性能,但不能多处挂载同时读写,
目前主要用在OpenStack上作为虚拟磁盘,而 Ceph 的文件系统接口读写性能较块设备接口差,但具有优异的共享性。
为什么 Ceph 的块设备接口不具有共享性,而 Ceph 的文件系统接口具有呢?
对于 Ceph 的块设备接口,如下图所示:

文件系统的结构状态是维护在各用户机内存中的,假设 Ceph 块设备同时挂载到了用户机1和用户机2,
当在用户机1上的文件系统中写入数据后,更新了用户机1的内存中文件系统状态,最终数据存储到了Ceph集群中。
但是此时用户机2内存中的文件系统并不能得知底层Ceph集群数据已经变化而维持数据结构不变,
因此用户无法从用户机2上读取用户机1上新写入的数据。
对于 Ceph 的文件系统接口,如下图所示:
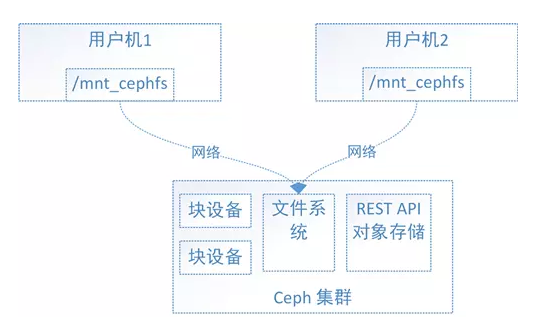
文件系统的结构状态是维护在远端 Ceph 集群中的,Ceph 文件系统同时挂载到了用户机1和用户机2。
当往用户机1的挂载点写入数据后,远端 Ceph 集群中的文件系统状态结构随之更新,
当从用户机2的挂载点访问数据时会去远端 Ceph 集群取数据,由于远端 Ceph 集群已更新,所有用户机2能够获取最新的数据。