本文讲述 Ceph 块设备存储的相关介绍以及 RBD 相关操作。
什么是块设备?
首先,块是一个字节序列(例如,一个 512 字节的数据块)。
块设备是 I/O 设备中的一类,是将信息存储在固定大小的块中,每个块都有自己的地址,
还可以在设备的任意位置读取一定长度的数据。最常见的块设备例如硬盘,U盘,SD卡等。
做一个不是很准确的但是方便你理解的概括:块设备就是以块作为存储单位的设备。
顺便提一下,与块设备相对应的 I/O 设备是 字符设备,它是在 IO 传输过程中以字符为单位进行传输的设备。例如键盘,打印机等。
Linux 系统下一般块设备都在 /dev/ 目录下,通常块设备(硬盘)连接到计算机之后,系统检测到有新的块设备,
就会自动在 /dev/ 目录下创建一个块设备文件,用户就可以通过这个文件去访问块设备。
通常会有 sda, sdb, hda, loop 等这样的块设备文件,其中以 sd 开头的块设备文件对应的是SATA接口的硬盘,
而以hd开头的块设备文件对应的是IDE接口的硬盘。以 loop 开头是循环设备,一般链接到某个文件。
RBD 是什么?
接下来回到我们的正题,那 rbd 是什么呢? rbd 就是由 Ceph 集群提供出来的块设备。
可以这样理解,sda 和 hda 都是通过数据线连接到了真实的硬盘,而 rbd 是通过网络连接到了 Ceph 集群中的一块存储区域,
往 rbd 设备文件写入数据,最终会被存储到 Ceph 集群的这块区域中。
接下来我们看看官网对 RBD 的介绍:
RBD : Ceph’s RADOS Block Devices , Ceph block devices are thin-provisioned,
resizable and store data striped over multiple OSDs in a Ceph cluster.
Ceph 块设备是精简配置的、大小可调且将数据条带化存储到集群内的多个 OSD 。从这句介绍中我们可以得到 RBD 下面的特性。
- RBD 就是 Ceph 里的块设备,挂载以后可以当普通的硬盘使用。
- resizable: 这个块可大可小。
- data striped: 数据条带化,这个块在 Ceph 里面是被切割成若干小块来保存的。
- thin-provisioned: 精简配置的,这个特性有点像虚拟机里面的
VDI磁盘,块的大小和在 ceph 中实际占用的大小是没有关系的,
并不是你创建 1 个 1GB 的块,它就得占 1GB 的空间。刚开始创建的块设备,甚至不占空间的,今后用多大空间,才会在 Ceph 中占用多大空间。
Ceph 块设备利用 RADOS 的多种能力,如快照、复制和一致性。
Ceph 的 RADOS 块设备( RBD )使用内核模块或 librbd 库与 OSD 交互。下图是 RBD 的基本架构:
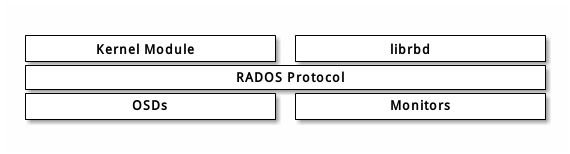
Note: 内核模块可使用 Linux 页缓存。对基于 librbd 的应用程序, Ceph 可提供 RBD 缓存。
环境说明
- 操作系统: Ubuntu 18.04 LTS
- Ceph 版本: 12.2.12 Luminous (stable)
如果你还没有安装好 Ceph 环境,请参考 Ceph-03 搭建 Ceph 存储集群
RBD 操作
RBD 的操作有很多,这里只列举几个常用的操作。
Note: 为了方便起见,下文我们统一用 rbd 来指代 Ceph 的块设备。
创建块设备
1 | root@ceph1:~# rbd create foo --size=1024 |
--size 是必须传入的参数,单位默认是 MB,你也可以指定成 GB,例如:
1 | rbd create foo --size=100G |
查看 rbd 的详细信息:
1 | root@ceph1:~# rbd info foo |
我们可以看到 Ceph 默认创建的 rbd 的默认格式是 format2 (Hammer 以及Hammer 之前默认的格式是 format1)。
我们再创建一个 format1 格式的 rbd:
1 | root@ceph1:~# rbd create foo-1 --size=1024 --image-format=1 |
我们可以看到虽然创建成功了,但是 Ceph 发出一个警告:”image format 1 is deprecated”,
可见在 Luminous 版本中 format1 格式的 rbd 已经被废弃了。我们再看下 foo-1 的信息:
1 | rbd image 'foo-1': |
我们可以看到 format1 和 format2 最明显的区别就是 block_name_prefix 的结构不一样。
接下来我们再看看文件结构:
1 | root@ceph1:~# rados -p rbd ls |grep foo |
format2 采用rbd_id.{rbd_name}的形式保存了这个块的 prefix,而 format1 采用的是 {rbd_name}.rbd 的形式。
下面对这两种格式进行简要的对比总结:
| 格式 | rbd_diretory | ID | prefix | data |
|---|---|---|---|---|
| format1 | 保存了所有 RBD 的名称 | foo.rbd | 在 ID 中 | 形如:rb.0.d372.327b23c6 |
| format2 | 空 | rbd_id.foo | 在 ID 中并在 rbd_header.prefix 显示输出 |
形如 rbd_data.d36b6b8b4567 |
除了上面意外 format1 和 format2 还有一个很重要的功能区别,那就是只有 format2 的 rbd 的才支持克隆。
这个后面在下文讲 rbd 克隆操作的时候还会提到。
默认创建的 rbd 的 object 大小是 4MiB(2 的 order 次方),我们也可以自己指定大小,例如:
1 | root@ceph1:~# rbd create foo-2 --size=1024 --object-size=8M |
如果没有指定,那么默认创建的 rbd 都会在 rbd 这个默认的存储池,如果你需要在其他存储池创建 rbd,可以通过下面的 2 种方式:
1 | root@ceph1:~# rbd create foo-3 --size=1024 --pool rbd2 |
映射块设备
命令形式:
rbd map {rbd_name}
例如:
1 | root@ceph1:~# rbd map test |
如果你的 rbd 格式是 format2,那么映射的时候可能会遇到如下错误:
1 | root@ceph1:~# rbd map foo |
出现这种错误的原因是 OS kernel 不支持块设备镜像的一些特性,所以映射失败。这种情况有是那种解决方案
方法一
直接diable这个rbd镜像的不支持的特性,首先查看该镜像支持了哪些特性:
1 | rbd image 'foo': |
可以看到特性 features 一栏,由于我 OS 的kernel只支持 layering,其他都不支持,所以需要把部分不支持的特性 disable 掉。
1 | root@ceph1:~# rbd feature disable foo exclusive-lock object-map fast-diff deep-flatten |
方法二
创建rbd镜像时就指明需要的特性,如:
1 | root@ceph1:~# rbd create foo2 --size 1024 --image-feature layering |
方法三
如果还想一劳永逸,那么就在执行创建rbd镜像命令的主机中,修改Ceph配置文件/etc/ceph/ceph.conf,在global section下,增加:
1 | rbd_default_features = 1 |
这里顺便提一下,这里 features 的配置是通过位运算开关来打开或者关闭某个 feature 的。所以如果你想开启 layering, exclusive-lock
支持,这里的 rbd_default_features 值就应该设置成 0x00011 也就是 3,依次类推,全部都打开就是 31(0x11111)。
重启 MON 服务之后生效 systemctl restart ceph-mon.target
挂载块设备
挂载之前,跟普通磁盘一样,你先得格式化:
1 | root@ceph1:~# mkfs.ext4 /dev/rbd2 |
然后挂载块设备
1 | root@ceph1:~# mkdir /mnt/rbd-foo |
Ceph RBD 支持 POSIX 标准,所以你可以像使用本地存储目录一样使用它。
开机自动挂载
有两种方法可以实现 Ceph rbd 的开机自动挂载。
方法一
我们知道 rbd 最所以不能像普通的硬盘设备一样开机自动挂载,是因为 Ceph 的 rbd 必须先经过映射(map)操作。
所以我们只需要把 rbd map foo 写入到开机启动脚本就好了。
不知道如何设置的同学请参考 ubuntu-18.04 设置开机启动脚本。
这里就不做赘述了。
方法二
Ceph 本身为我们提供了一种更高级的自动映射 rbd 的方法。
首先我们需要在部署节点上把客户端验证的 key 推送到客户端。
1 | ceph-deploy admin ceph-client |
然后我们编辑客户端的 rbdmap 文件 vim /etc/ceph/rbdmap,添加一行自动 map 的配置:
1 | rbd/{rbd_name} id=admin,keyring=/etc/ceph/ceph.client.admin.keyring |
{rbd_name} 是你需要自动 map 的 rbd 名称,比如你改成 foo,这样 Ceph 就会在开机的时候自动映射 foo 块设备。
接下来就简单了,我们可以像普通硬盘一样开机挂载了。编辑 /etc/fstab,添加一行自动挂载的配置
1 | /dev/rbd/rbd/{rbd_name} /mnt/rbd ext4 defaults,noatime,_netdev 0 2 |
这里的 {rbd_name} 同样需要改成对应的 rbd 实际名称,同时需要注意加上 _netdev 选项,表示是网络设备。
RBD 删除
这个非常简单,命令形式如下:
rbd rm {pool_name}/{rbd_name}
例如:
1 | rbd rm rbd/foo |
RBD 快照
创建快照:
rbd snap create {rbd_name}@{snap_name}
例如:
1 | rbd snap create foo@foo-snap-01 |
删除快照:
rbd snap rm {rbd_name}@{snap_name}
例如:
1 | rbd snap rm foo@foo-snap-01 |
快照回滚,如果不小心删除数据了,并且之前有创建快照的话,可以使用快照回滚:
rbd snap rollback {rbd_name}@{snap_name}
例如:
1 | root@client:# rbd snap rollback foo@foo-snap-01 |
Note: 回滚之前要先 umout 块设备,回滚之后再重新 mount。
通过快照克隆 RBD
首选,被克隆的 rbd 格式必须是 format2
(1)克隆之前,先保护快照,以免被修改。
1 | rbd snap protect foo@s_foo_1 |
(2)克隆
1 | rbd clone foo@s_foo_1 clone_foo |
此时我们可以看到 clone_foo 的 parent 属性为 rbd/foo@s_foo_1,表示引用的是 rbd/foo@s_foo_1 快照
(3)脱离
现在 clone_foo 还是跟 rbd/foo@s_foo_1 关联在一起的。还不是一个独立的 rbd,所以我们需要把他们脱离:
1 | root@client:# rbd flatten clone_foo |
脱离之后 clone_foo 就是一个独立的 rbd 了。
RBD 扩容
RBD 的扩容分 2 步:
- 扩展块大小
- 扩展 fs(文件系统)
Ceph 块设备映像是精简配置,只有在你开始写入数据时它们才会占用物理空间。然而,它们都有最大容量,就是你设置的 –size 选项。
如果你想增加(或减小) Ceph 块设备映像的最大尺寸,执行下列命令:
1 | rbd resize --size 2048 foo #增加块设备容量 |
如果 rbd 已经被挂载了,扩容/缩容之后还需要扩展挂载 rbd 的文件系统,否则不会生效。
ext4 文件系统扩容:
1 | resize2fs /dev/rbdxxx |
xfs 文件系统扩容:
1 | xfs_growfs /dev/rbdxxx |
RBD 缩容
Note: xfs 文件系统不支持文件系统缩小,只能增大,ext4 文件系统支持扩大和缩小
RBD 缩容比较麻烦,分为 4 步:
- 先卸载文件系统 umout /dev/rbd0
- 检测文件系统 e2fsck -f /dev/rbd0
- 缩小文件系统 resize2fs /devrbd0 400M
- 缩小块大小 rbd resize –image rbd1 –size 400 –allow-shrink
注意,上面的步骤不能乱,要严格按照顺序执行。操作完之后,要记得检查块设备里面的文件是否可以正常访问,是否有损坏。