从本文开始我们一起学习一下如何使用当前比较成熟的分库分表框架 Sharding-JDBC 实现分库分表,读写分离,以及自定义分库分表算法。
Sharding-JDBC 简介 Sharding-Sphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)
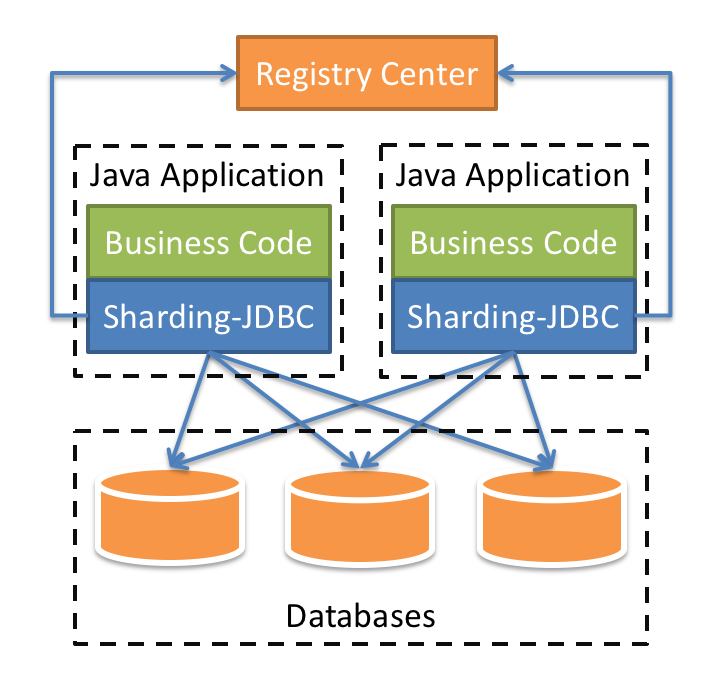
ShardingSphere 定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,Sharding-Sphere 的架构图。
Sharding-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,
适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
概念解释 在快速开始之前我们先要对后面要用到的一些概念进行一些解释。
逻辑表 水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为10 张表,
真实表 在分片的数据库中真实存在的物理表。即上个示例中的t_order_0到t_order_9。
数据节点 数据分片的最小单元。由数据源名称和数据表组成,例:ds_0.t_order_0。
绑定表 指分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。
1 SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id= i.order_id WHERE o.order_id in (10 , 11 );
在不配置绑定表关系时,假设分片键order_id将数值10路由至第0片,将数值11路由至第1片,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:
1 2 3 4 SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id= i.order_id WHERE o.order_id in (10 , 11 );SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id= i.order_id WHERE o.order_id in (10 , 11 );SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id= i.order_id WHERE o.order_id in (10 , 11 );SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id= i.order_id WHERE o.order_id in (10 , 11 );
在配置绑定表关系后,路由的SQL应该为2条:
1 2 SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id= i.order_id WHERE o.order_id in (10 , 11 );SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id= i.order_id WHERE o.order_id in (10 , 11 );
其中 t_order 在 FROM 的最左侧,ShardingSphere 将会以它作为整个绑定表的主表。所有路由计算将会只使用主表的策略,
如何将两个表绑定呢?很简单,只要把他们的分区(包括分表和分库)键设置为同一个就可以了。
分片键 简单来说就是用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。SQL中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片。
快速开始 概念解释完了,本着能动手就别吵吵的原则,我直接开搞,实战演练。
1. 建库、建表 假设我们有个业务逻辑表 t_user 现在要分表分库,假设我们分成两个库(demo_ds_0,demo_ds_1),
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 CREATE DATABASE demo_ds_0 CHARSET= utf8;use demo_ds_0; DROP TABLE IF EXISTS `t_user_0`;CREATE TABLE `t_user_0` ( `user_id` bigint (20 ) AUTO_INCREMENT, `username` varchar (30 ) NOT NULL , `password` varchar (30 ) DEFAULT NULL , PRIMARY KEY (`user_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8; DROP TABLE IF EXISTS `t_user_1`;CREATE TABLE `t_user_1` ( `user_id` bigint (20 ) AUTO_INCREMENT, `username` varchar (30 ) NOT NULL , `password` varchar (30 ) DEFAULT NULL , PRIMARY KEY (`user_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8; CREATE DATABASE demo_ds_1 CHARSET= utf8;use demo_ds_1; DROP TABLE IF EXISTS `t_user_0`;CREATE TABLE `t_user_0` ( `user_id` bigint (20 ) AUTO_INCREMENT, `username` varchar (30 ) NOT NULL , `password` varchar (30 ) DEFAULT NULL , PRIMARY KEY (`user_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8; DROP TABLE IF EXISTS `t_user_1`;CREATE TABLE `t_user_1` ( `user_id` bigint (20 ) AUTO_INCREMENT, `username` varchar (30 ) NOT NULL , `password` varchar (30 ) DEFAULT NULL , PRIMARY KEY (`user_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8;
2、新建 SpringBoot 项目 这里直接使用 IDEA 的 spring-boot-initializer 建立了一个demo工程,工程名为 sharding-jdbc-spring-boot-demo,
下面贴上完整的 pom.xml 文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 <?xml version="1.0" encoding="UTF-8" ?> <project xmlns ="http://maven.apache.org/POM/4.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" > <modelVersion > 4.0.0</modelVersion > <parent > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-parent</artifactId > <version > 2.1.5.RELEASE</version > <relativePath /> </parent > <groupId > org.rockyang</groupId > <artifactId > sharding-jdbc-spring-boot-demo</artifactId > <version > 0.0.1-SNAPSHOT</version > <name > sharding-jdbc-spring-boot-demo</name > <description > Demo project for sharding-jdbc</description > <properties > <project.build.sourceEncoding > UTF-8</project.build.sourceEncoding > <project.reporting.outputEncoding > UTF-8</project.reporting.outputEncoding > <java.version > 1.8</java.version > </properties > <dependencies > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-web</artifactId > </dependency > <dependency > <groupId > io.shardingsphere</groupId > <artifactId > sharding-jdbc-spring-boot-starter</artifactId > <version > ${sharding-jdbc-spring-boot-starter.version}</version > </dependency > <dependency > <groupId > org.mybatis.spring.boot</groupId > <artifactId > mybatis-spring-boot-starter</artifactId > <version > 2.1.0</version > </dependency > <dependency > <groupId > com.alibaba</groupId > <artifactId > druid</artifactId > <version > 1.1.6</version > </dependency > <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > <version > 5.1.30</version > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-test</artifactId > <scope > test</scope > </dependency > </dependencies > <build > <plugins > <plugin > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-maven-plugin</artifactId > </plugin > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-compiler-plugin</artifactId > <configuration > <source > ${java.version}</source > <target > ${java.version}</target > <skip > true</skip > </configuration > </plugin > </plugins > </build > </project >
3、配置文件 application.properties 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 server.port =9001 initialSize =5 minIdle =5 maxIdle =100 maxActive =20 maxWait =60000 timeBetweenEvictionRunsMillis =60000 minEvictableIdleTimeMillis =300000 sharding.jdbc.datasource.names =ds0,ds1 sharding.jdbc.datasource.ds0.type =com.alibaba.druid.pool.DruidDataSource sharding.jdbc.datasource.ds0.driver-class-name =com.mysql.jdbc.Driver sharding.jdbc.datasource.ds0.url =jdbc:mysql://localhost:3306/demo_ds_0 sharding.jdbc.datasource.ds0.username =root sharding.jdbc.datasource.ds0.password =123456 sharding.jdbc.datasource.ds0.initialSize =${initialSize} sharding.jdbc.datasource.ds0.minIdle =${minIdle} sharding.jdbc.datasource.ds0.maxActive =${maxActive} sharding.jdbc.datasource.ds0.maxWait =${maxWait} sharding.jdbc.datasource.ds0.validationQuery =SELECT 1 FROM DUAL sharding.jdbc.datasource.ds0.timeBetweenEvictionRunsMillis =${timeBetweenEvictionRunsMillis} sharding.jdbc.datasource.ds0.minEvictableIdleTimeMillis =${minEvictableIdleTimeMillis} sharding.jdbc.datasource.ds1.type =com.alibaba.druid.pool.DruidDataSource sharding.jdbc.datasource.ds1.driver-class-name =com.mysql.jdbc.Driver sharding.jdbc.datasource.ds1.url =jdbc:mysql://localhost:3306/demo_ds_1 sharding.jdbc.datasource.ds1.username =root sharding.jdbc.datasource.ds1.password =123456 sharding.jdbc.datasource.ds1.initialSize =${initialSize} sharding.jdbc.datasource.ds1.minIdle =${minIdle} sharding.jdbc.datasource.ds1.maxActive =${maxActive} sharding.jdbc.datasource.ds1.maxWait =${maxWait} sharding.jdbc.datasource.ds1.validationQuery =SELECT 1 FROM DUAL sharding.jdbc.datasource.ds1.timeBetweenEvictionRunsMillis =${timeBetweenEvictionRunsMillis} sharding.jdbc.datasource.ds1.minEvictableIdleTimeMillis =${minEvictableIdleTimeMillis} sharding.jdbc.config.sharding.tables.t_user.actual-data-nodes =ds${0..1}.t_user_${0..1} sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column =user_id sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression =ds${user_id % 2} sharding.jdbc.config.sharding.tables.t_user.table-strategy.inline.sharding-column =user_id sharding.jdbc.config.sharding.tables.t_user.table-strategy.inline.algorithm-expression =t_user_${(user_id % 5) % 2} sharding.jdbc.config.sharding.tables.t_user.key-generator-column-name =user_id spring.shardingsphere.sharding.tables.t_user.key-generator.column =user_id spring.shardingsphere.sharding.tables.t_user.key-generator.type =SNOWFLAKE spring.shardingsphere.sharding.tables.t_user.key-generator.props.worker.id =1 spring.shardingsphere.sharding.tables.t_user.key-generator.props.max.tolerate.time.difference.milliseconds =0 spring.shardingsphere.props.sql.show =true logging.level.org.rockyang.shardingjdbc.common.mapper =DEBUG logging.level.org.springframework =INFO mybatis.configuration.cache-enabled =false
Application 1 2 3 4 5 6 7 8 9 10 @SpringBootApplication @MapperScan("org.rockyang.shardingjdbc.common.mapper") public class DBTableApplication { public static void main (String[] args) { SpringApplication.run(DBTableApplication.class, args); } }
User 实体类定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 public final class User { private Long userId; private String username; private String password; public User () { } public User (Long userId) { this .userId = userId; } public User (String username, String password) { this .username = username; this .password = password; } public User (Long userId, String username, String password) { this .userId = userId; this .username = username; this .password = password; } public long getUserId () { return userId; } public void setUserId (long userId) { this .userId = userId; } public String getUsername () { return username; } public void setUsername (String username) { this .username = username; } public String getPassword () { return password; } public void setPassword (String password) { this .password = password; } @Override public String toString () { return "User{" + "userId=" + userId + ", username='" + username + '\'' + ", password='" + password + '\'' + '}' ; } }
Mapper 以及 Service UserMapper.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Mapper public interface UserMapper { Integer insert (User model) ; List<User> selectAll () ; }
UserMapper.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace ="org.rockyang.shardingjdbc.common.mapper.UserMapper" > <insert id ="insert" useGeneratedKeys ="true" keyProperty ="userId" parameterType ="org.rockyang.shardingjdbc.common.model.User" > INSERT INTO t_user (username, password ) VALUES (#{username},#{password}) </insert > <select id ="selectAll" resultType ="org.rockyang.shardingjdbc.common.model.User" > select t.user_id as userId, t.username as username, t.password as password from t_user t </select > </mapper >
UserService
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public interface UserService { Integer add (User user) ; List<User> selectAll () ; }
UserServiceImpl
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Service public class UserServiceImpl implements UserService { @Resource UserMapper userMapper; @Override public Integer add (User user) { return userMapper.insert(user); } @Override public List<User> selectAll () { return userMapper.selectAll(); } }
开始测试 我们通过编写单元测试的方式来测试分表分库功能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 @RunWith(SpringRunner.class) @SpringBootTest public class UserServiceTest { private static Logger logger = LoggerFactory.getLogger(UserServiceTest.class); @Autowired private UserService userService; @Test public void testAdd () { String username = StringUtil.generateRandomString(20 ); String password = StringUtil.generateRandomString(20 ); User user = new User (username, password); userService.add(user); logger.info("userId: {}" , user.getUserId()); } @Test public void testAddBatch () { String username; String password; for (int i = 0 ; i < 100 ; i++) { username = StringUtil.generateRandomString(20 ); password = StringUtil.generateRandomString(20 ); User user = new User (username, password); userService.add(user); logger.info("userId: {}" , user.getUserId()); } } @Test public void testSelect () { List<User> users = userService.selectAll(); logger.info("Total records: {}" , users.size()); for (User user : users) { logger.info("{}" , user); } } }
总结
分表的策略不能跟分库一样,比如都用 user_id 取模的话,那么就会出现每个数据库中都有一半的数据表没有数据,比如 demo_ds_0 中的t_user_${(user_id % 5) % 2} 这种先对一个基数取模来解决这个问题。
Sharding-JDBC 的查询是使用归并的形式,将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端。详细的算法归并引擎
Sharding-JDBC 内置的 SNOWFLAKE 生成ID的算法有缺陷,它只区分了 workerId(工作进程ID),没有区分dataCenterId(数据中心ID)。
项目源码链接 sharding-jdbc-spring-boot-demo
参考链接